우리에게 데이터가 주어졌을때 기술통계값으로 데이터를 관찰하는 것은 필수적이다.
대략적인 데이터의 분포를 볼 수 있고, 이상값은 얼마나 있는지, 평균은 어느정도 되는지, 중앙값과 평균의 차이는 얼마나 되는지 등 기술통계값으로 대략적인 데이터의 분포 파악이 가능하다.
우선, 데이터의 기술통계값을 describe()를 사용하여 요약하여 보자.
* df 는 데이터 셋을 담은 변수이다. *

-> describe 를 사용하면, 데이터의 수, 평균, 표준편차, 최소값, 1,2,3사분위수, 최대값을 볼 수 있다.
* 2사분위수와 중앙값은 같은 값이다.
개별 기술통계값 구하기
개별 기술통계값은 이러하다.

개별 기술통계값을 알고 싶으면, 위에 나온 명령어를 사용하면 된다.
* 나는 '위도' 데이터의 값이 궁금해서 '위도'의 기술통계값을 구하였다.
df["위도"].count() # 결측치를 제외한 값의 갯수
df["위도"].mean() # 위도의 평균
df["위도"].max() # 위도의 최댓값
df["위도"].min # 위도의 최솟값
* 표준편차를 구하는 방법
1. numpy 를 활용하여 var()의 제곱근을 구한다.

2. std 명령어 사용
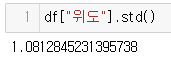
표준편차?
-> 표준편차는 자료의 산포도를 나타내는 수치로, 분산의 양의 제곱근이다.
표준편차 값이 작을수록 평균값에서 변량들의 거리가 가깝다는 말이다.
쉽게 말해서, 표준편차가 작다면 데이터들이 다닥다닥 붙어있어서 평균값과 차이들이 많이 없다는 소리고,
표준편차가 크다면 데이터들이 평균값과 차이가 나는 데이터들이 많다는 것이다.
[출처]: 인프런, "공공데이터로 파이썬 데이터 분석 시작하기" 박조은 선생님 강의
파일 출처: 공공데이터포털, 소상공인시장진흥공단_상가정보_API
'Python 을 활용한 데이터분석' 카테고리의 다른 글
| 상관계수, 산점도, 회귀분석 (0) | 2022.02.14 |
|---|---|
| 단변량 수치 변수 시각화 (0) | 2022.02.14 |
| 행, 열을 기준으로 값을 가져오기 (0) | 2022.02.10 |
| 결측치 시각화, 필요없는 컬럼 제거하기(Missingno, drop) (0) | 2022.02.10 |
| 상가 정보 데이터 불러오기 및 데이터 정보 확인 하기 (0) | 2022.02.09 |